Large language models are amazing. And terrible. Impressive. Complex. And daunting. Mostly, they are capricious. However, they are also improving at such a rate, bad experiences now can become productive ones tomorrow.
So I thought I’d document the most satisfying / least frustrating solution I’ve found to date. Next week, it will undoubtably be superseded.
For some context, I am doing this on the basic Mac M1 Max: 20 GPU cores and 32GB memory. It also has 10 CPU cores, but as it turns out, these are pretty much redundant for ML purposes (yes, I’m trying to avoid the marketing term “AI”).
I did buy a M4 Mac mini to run as a ML server, only to discover that while its 10 core GPU slowed things down compared to the Max, its 16GB of memory severely limited model choice to less capable options.
As for myself, until very recently I had near-zero interest in “AI” at all, and absolutely no experience with any of the terminology.
In my exploratory phase of ML, I started with Ollama, then tried Swama, as I liked the sound of speed improvements from a platform written in Swift and utilising Apple’s new MLX technology.
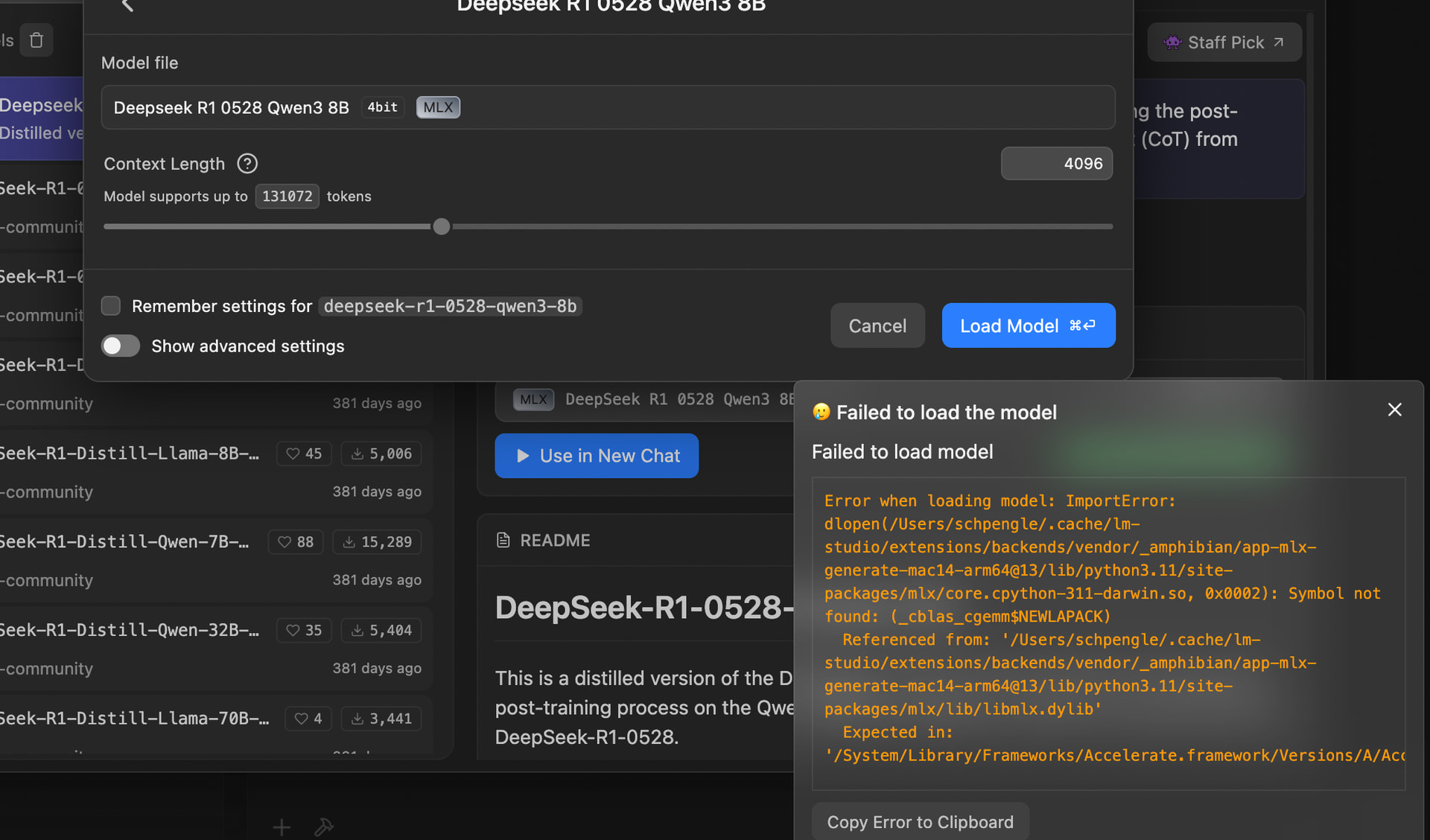
The problem was both seemed too hard to put all the pieces together. Eventually (and recently) I’ve gone to LM Studio. It was simple to instal (just an app) and included a chat interface, model repository and management, plus advanced mode for playing around with the small bits, as well as headless server.
I think that’s enough of the background. Now for the process of getting it up and running…